
 In today’s world, there is a lot of hype surrounding social media — unsurprisingly, considering the medium itself created the very concept of going viral.
In today’s world, there is a lot of hype surrounding social media — unsurprisingly, considering the medium itself created the very concept of going viral.
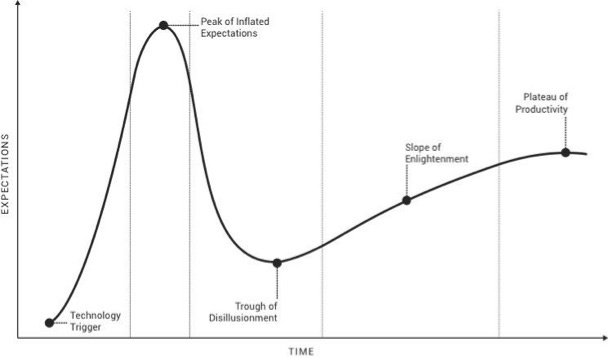
According to the Gartner hype curve for new technologies, a period of hype and inflated expectations is followed by the “trough of disillusionment” during which we become more critical of a new concept or technology we’ve bought into and believed in its inherent value. Questions ensue.
Does it really do what it promised? How do I know I can trust this data? Am I getting ROI out of this? It’s during this latter phase where the new technology has to mature and prove that it is worthy to become a stable, ongoing part of our world. This is where I believe social media is today, and now is the time for social to prove its credentials as a research methodology.
In my experience, it doesn’t take much to convince people that there is huge potential value within social data for understanding consumers more deeply. It’s a bit of a no-brainer, in theory, that all of this unprompted conversation would contain insights into how people think and feel, what they care about, what they’re worried about, and what they need and want.
Any form of consumer research is at best a version of the true experiences of groups of individuals. It’s impossible for any one method to perfectly encapsulate and understand complex human experience. The more sources in your research mix, the more accurate the picture you’re building will become. So, while I would never suggest that social should replace other forms of market research, it would certainly be a missed opportunity to exclude this incredibly rich new data source from your research mix.
Many market researchers have held back from fully embracing a social research methodology or incorporating social into their research mix in a fully integrated way. In my opinion, this is not due to a lack of understanding of the potential opportunity for finding valuable insight, but to the perceived issues and limitations of this type of data.
The rise of insight-driven business has positioned the market researcher at the center of some of the most important strategic decisions that are made in many of the world’s largest companies. To better understand the potential challenges and barriers with adopting social research methodology, I conducted interviews with a number of highly experienced and talented CMI (consumer market insights) professionals. There were two recurring themes within these interviews:
- Representation is a concern. Social media data is created by a self-selecting group, which differs from channel to channel and doesn’t necessarily reflect the broader online and offline population. This poses the question: can I use this data to help understand a whole consumer group, or only those I’m hoping to reach via social channels?
- Social data is often “sold” as being less biased than other research methods, although in reality, it’s not. Unlike tried-and-tested methodologies, we don’t understand how to reduce the biases within this dataset.
Both are completely valid concerns that resonate strongly with me as a researcher. However, neither should prevent you from using social as a research methodology. Let’s address each issue.
Overcoming Representation Issues
It’s true that social data as a whole is unlikely to fully represent the offline world in the way that a weighted panel can because a selection bias exists within social data. That doesn’t mean that it’s impossible to understand aspects of offline consumers, but it does need to be considered in the methodology.
Just as you wouldn’t serve a survey to everyone in a panel (you select your target audience), you don’t have to listen to everyone on social media all at once. You can select an audience based on many different characteristics, demographics, life stages, and interests. You can then benchmark those audiences to understand how they think differently about different subjects or weight the data from different groups to better model it against the offline population.
Overcoming the Biases in Social
The first stage in mitigating any bias is to acknowledge and understand the problem. Social, like all other forms of research, is vulnerable to bias. We discussed selection bias above, but here are three more stages in your analysis where you should be careful to avoid biases creeping in:
1) Data collection: Boolean search strings are incredibly flexible and allow you to gather and segment data in almost any way, but they are open to bias if proper care and attention are not paid. If you don’t fully research the key terms and phrases for a given topic, all social handles for a brand, relevant hashtags, common misspellings and typos or slang terms that could possibly exist, you could be biasing your data toward people who think and speak like you. Even if you know a topic well, it’s still important to do some desk research to make sure you’re challenging your assumptions to reduce bias in your data collection.
2) Data segmentation: You can segment your data using Boolean by categorizing and benchmarking within your dataset. As with the query, it’s important to invest time into researching topics within your data to avoid skewing it toward trends that you already know about. For a truly data-lead segmentation, the best approach is to take a representative random sample of conversation and code it manually for themes as they emerge. This allows you to discover new topics, reduce the bias inherent in searching for topics you already know about, and get more granular in your themes. A human can detect far more subtleties in tone, emotion, and context, which is where the data is at its most rich and insightful.
3) Interpretation biases: All research, particularly qualitative research, involves interpretation of themes by a human analyst, and so is open to researcher or interpretation bias. Being cognizant of this is the most important factor for reducing its impact. A representative coded sample is also helpful in challenging your assumptions as a researcher. It’s important to remember that you are telling the consumer’s story, not your own.
There is another factor, which I believe is the greatest challenge not only for social data but all forms of business intelligence. The rise of self-serve digital research platforms means that non-CMI professionals can now create and analyze surveys and track web metrics and social data themselves. This presents huge opportunities to truly distribute insights throughout the business and allow us to actually realize the lofty aim of being an insight-driven business.
It also presents a significant challenge. The word “insight” is prone to overuse and as a result, is frequently misunderstood. An insight is not a chart or a number, but rather an idea communicated from one human to another to convey a way you could do something differently, better, or new.
The journey from data to insight, and from insight to action, contains two bridges that are reliant on human interpretation, communication, and understanding. Opening this process up to more humans increases the risk for human error, and for muddying the water of research with opinion.
One approach to combat this is a central CMI team that produces and distributes insight throughout the business, and this can work really well. However, it’s my view that in the long-term the role of the CMI professional isn’t going to be fighting against distributed power to find insight, but will set the guardrails that enable different teams to explore data safely, and generate robust, impactful insights themselves.
When we achieve this, it will be possible to build a fully insight-driven business.

About the Author: Bex Carson is the Global Director of Research Services at Brandwatch.
